Portfolio
: Monotone computing on incomplete information
is a project that I developed during the latter two years of my PhD program (which I mastered out of). I am not knowledgeable on the topic of distributed systems. Nonetheless, seeks to solve a distributed systems problem that was presented to me by my collaborators. It can be described as follows:
A process running in a distributed system often needs to compute on values that are approximate: some of the information of such a value (an approximation) is stored locally, while the rest of the information is only accessible elsewhere in the system. When coordination to consolidate a value’s full information locally isn’t feasible or performant, we may choose to apply a function to an approximate argument. But how do we know if such applications are “correct” or “safe”?
If the function we wish to apply is monotone, then applying it to an approximate input is guaranteed to produce an approximate output. Logic and Lattices for Distributed Computing presents a language called , in which certain functions are annotated as monotone. This allows the programmer to apply them to approximate shared data without the need for coordination, which Conway et al. view as a costly bottleneck. However, has no means to determine whether or not the annotations are correct! In contrast, provides an expressive collection of monotone primitives and a monotonicity-aware type system, allowing the programmer to implement ’s examples without the need for trusted user annotations. Here is an example program:
types
// a set of non-negative integers
NatSet = Nat |> Prop;
in
let mSum =
fun (x : NatSet) @(+ x)
let extract to Nat with n v acc = x
in (plus n acc)
end
end
in
// Output: 6
(mSum { 1 -> known, 2 -> known, 3 -> known : NatSet })
end
All types in are endowed with information orderings. The primitive type is the set of natural numbers, with the standard “less than or equal to” ordering . is the two element type containing the values and , ordered such that .
is the type of finite sets of natural numbers, ordered by set inclusion. These sets are not sets as we would typically think of them, because they are incomplete: a set value indicates a set which contains at least the elements , , and , and potentially additional elements as well. We therefore write the set using the more cumbersome notation . All other elements are not stored in our data representation of the set, and they implicitly map to .
The function takes a as its input and produces the sum of the ’s elements as output. The expression is a coeffect ascription, which statically asserts that the function is monotone.
The body of the function uses an extract expression, which binds three variables , , and in its body . It computes the following sequence of intermediate values , substituting each element for n and the previous iteration for in .
(here 0 is chosen because it is the smallest natural number)
At this point all elements of the set have been exhausted, and so we return 6.
This may seem like a convoluted and inefficient way to sum a set of natural numbers. However, it is implemented using a general elimination form extract which is carefully designed transform its input set monotonically. Importantly, the type system ensures that influences the body of the extract form monotonically. Changing to generates the type error “Expected monotone usage of acc but found antitone”, and for good reason: then we would have
even though , making mSum non-monotone!
Why prove this function monotone at all? Recall that a value is an incomplete view of a set. When we sum its elements, we are potentially only summing a proper subset of the exact set’s elements. The monotonicity of therefore tells us that when applied to an incomplete input set , produces a lower bound on the sum of the elements of the exact set that we are approximating (some superset of ). A typchecker and interpreter for can be found here. I also formalized the type system, and implemented an embedding into Agda here here. I’ve included an optional, more detailed explanation below.
Show details
Motivation
Inconveniently, a process running in a distributed system has a local view of the system: Information relevant to its execution may be contained in some other process’s address space. While inter-process coordination can ensure that a process acts only on globally up-to-date information, distributed systems researchers have identified such coordination as a bottleneck. However, they’ve also proposed a strategy to mitigate this bottleneck: Allow processes to compute upon incomplete information. In the latter half of my ill-fated time as a PhD student, I developed a type system to determine if computations on incomplete information are sound.
Here is a toy example demonstrating this approach. Imagine developing a system to manage advertisements in a mobile game. A client advertiser may purchase a contract to display their advertisement some natural number times. Since this mobile game may be played without internet connectivity, a counter tracking the number of times this advertisement has been viewed is replicated across the players’ mobile devices.
The ad counter is represented as a dictionary which maps each player identifier to a natural-valued lower bound on the number of times that player has viewed the ad.
Alice: { Alice -> 1, Bob -> 0 }
Bob: { Alice -> 0, Bob -> 2 }
Here player Alice has viewed the advertisement once, Bob has viewed it twice, and no coordination has been performed between the two players. A replicated counter can be thought of as an information repository or knowledge state, e.g., Alice “knows” that she has viewed the advertisement at least once and that Bob has viewed it at least 0 times. No process in the system has perfect knowledge, which is obtained from taking the pointwise maximum of all counter replicas in the system:
Perfect (global) truth: { Alice -> 1, Bob -> 2 }
Nonetheless, when the game starts Alice must decide whether or not to show this particular advertisement on the basis of her local view. To do so, she stores the summation over the lower bounds stored in her dictionary and then computes the quantity . If this quantity is true, Alice knows that the contract has been fulfilled, and that some other ad should be shown if at all possible. Otherwise, displaying this advertisement may be a reasonable option. Even though Alice’s dictionary contained incomplete information, the computation was still sound; this is because its output is monotone as a function of its input, and its input is monotone as a function of time (i.e., an ad cannot be “unseen”, and so the counter’s entries cannot be decremented).
Many useful computations are non-monotone. For example, taking the average of a dictionary’s entries is a non-monotone function; it would not be safe to compute a dictionary’s average value from one of its local views. Thus I was motivated to develop a type system for distinguishing between monotone and non-monotone computations.
A digression on effects
Arguably, in a function type , the domain can be considered a cause and the codomain can be considered an effect. But when programmers and computer scientists speak of effects, they clearly are not talking about codomains. So just what the heck are they talking about?
They are talking about side effects. A side effect that portion of the an effect that is threaded implicitly through a computation. To understand what I mean by this, let’s look at a concrete example.
match (300 / x) with
| Val y →
match (lookup myArray y) with
| Val z → z
| Error → Error
| Error → Error
This program divides by some integer and then uses the result to index into an array. There are two points at which the program may throw an error. First, the division operation may throw a division-by-zero error. Second, the array lookup may throw an index-out-of-range exception. This yields two levels of indentation to check each error. But forcing the user to handle each error seems like a distraction, because typically we want to handle all errors in the same manner: by halting the program. The code should describe the computation that is expected to happen rather than unexpected errors; that is, the programmer should instead write the following code:
let y = (3 / x) in
lookup myArray y
In the above snippet, errors are treated as an implicit side-effect. Achieving such a simplification in a declarative mathematical setting is an interesting trick, first discovered by Moggi.
type T ’A = Val of ’A | Error
The above definition of the type constructor maps a type parameter to the variant type . That is, a value of type is either a value of type or . Now, an error-prone computation has the type . For example, the division operator has type , meaning that it maps a pair of integers to either an integer or an error.
We’re left with the problem that a computation of type does not seem to compose with a computation of type , because the codomain of the former does not match the domain of the latter. Two properties of enable a solution.
First, is functorial, which entails among other things that given a function , we can produce a function .
functorT f x = match x with Val a → Val (f a) | Error → Error
Second, for each type , we have a multiplication transformation of type .
mu x =
match x with
| Val (Val y) → Val y
| Val (Error) → Error
| Error → Error
With these two components, we can combine effectful computations and into the composite .
Monotonicity coeffects
In the above section, we’ve seen how it can be useful implicitly thread a side effect through a computation. It can also be useful to implicitly thread a side cause through a computation. Here is a rough analogy. Imagine that you are painting a bird house. This process has two inputs: a can of paint and an unpainted birdhouse. It has one output: a painted birdhouse. However, painting the birdhouse does not fully consume the can of paint; the actual amount of paint used can be considered a coeffect or a side cause. Though we did not begin the painting knowing exactly how much paint was used, the task of painting the birdhouse nonetheless revealed the exact amount. Below, we introduce coeffects and show how they can be used to prove program functions monotone.
To reason about the monotonicity of programs, we first interpret each type as a poset .
The posets of primitive types such as are built-in:
The posets of composite types such as (the type of pairs whose first component belongs to and whose second component belongs to ) are constructed inductively:
A typical typing judgment has the form , where:
- is a program expression
- is a mapping from the free variables of to their types, called a “typing context”
- is the type of the expression
A typing context has the form , meaning that variable has type , has type , etc. The typing context and program expression are provided as inputs to the type checking algorithm, while the result type is produced as an output. A typing context is interpreted as the product of the interpretations of its types: . A typing judgment is interpreted as a function of type .
Since our types and typing context denotes posets, we can interpret more specifically as a monotone function. Suppose that for we would like to compute . However, there is a problem: we do not have access to . Instead, we have a local view of our desired input, i.e., some such that . Since is monotone, we have . Approximate inputs allow us to obtain an approximation of the result that we would have obtained if we had access to exact inputs.
We can only derive an approximate output from approximate inputs if our program is monotone separately as a function of each of its free variables, i.e., for each argument position we have implies . However, most useful computations are not monotone. If a computation depends non-monotonically on some parameter, receiving an exact input in that parameter is sufficient to ensure that we produce a lower bound on our desired exact output. For example, consider this typing judgment.
Here is truncated subtraction, which is like standard subtraction but rounds results which would be negative up to 0. This computation depends monotonically on and non-monotonically on ; the purpose of monotonicity coeffects is to synthesize this fact automatically from the expression . A monotonicity type-and-coeffect judgment has the following form.
We’ve extended the standard typing judgment with an additional component , called the coeffect. It is a vector whose length matches that of , and which contains one coeffect scalar (either for monotone or for arbitrary) corresponding to each variable in . Our subtraction example becomes:
The coeffect of this type-and-coeffect judgment communicates that in order to produce a lower bound on our desired output, we require a lower bound on the argument supplied for and the exact value of the argument supplied for . We previously noted that while and are inputs of our type checking algorithm, is an output. , like , is an output of the type checking algorithm.
We modeled effectful functions from to using a functorial type operator , as functions of type . Coeffects are in some sense the opposite, where coeffectful functions (functions which implicitly pull in resources from context) are modeled using a functorial transformation , as functions (in our case monotone functions) of type . Monotonicity coeffects are graded, meaning that we modify our functions’ domains using a family of scalar-indexed functorial transformations rather than just a single transformation . The functorial transformations on posets , for , are defined as follows
- The transformation produces its argument as output, i.e. it is the identity function.
- The transformation produces an output that is equal to its argument except with all non-reflexive edges removed.
We provide depictions of and below, in which reflexive edges are implicitly assumed on all elements, and an upward edge from node to node means that .
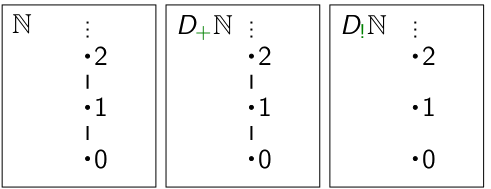
The meaning of is quite clear; since , simply represents the set of monotone functions from to .
is slightly more subtle. A poset with only reflexive edges is called discrete.
can therefore be though of as the discretifying transformation.
If and are posets, and if is discrete, then consider the meaning
of the statement “The function ” is monotone. This is in fact a
vacuous statement. It guarantees that preserves reflexive edges. However,
all functions preserve reflexive edges; when we apply to two reflexively
related (equal) elements, of course the resulting outputs will be comparable, because
they will be exactly the same. is thus the set of arbitrary
functions from to . Though includes both
monotone and non-monotone functions from to , we can use it as a
coarse overapproximation of the set of non-monotone functions from to .
A typing judgment is then interpreted as a monotone function of type . For example, the typing judgment is then interpreted as a monotone function of type .
To compose two coeffectful functions we have a family of graded comultiplication functions , where is a binary scalar composition operator defined as follows (with left operand along the left side and right operand along the top):
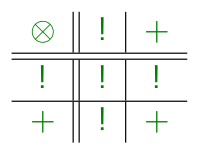
Ours is a degenerate coeffect system in which for all posets and all scalars and we have . Thus we define , the identity function on .
With graded comultiplication, we can compose coeffectful functions: from
and we obtain the composite:
Typed Lua Class System
(For a full description of this project, see A Class System for Typed Lua
In the Summer of 2016, I participated in the Google Summer of Code, working with LabLua as a mentorship organization, under the guidance of Prof. Fabio Mascherenas. My task was to develop a class system for Typed Lua, an optionally typed variant of Lua.
I had previously developed my own typed class system for Lua (see below), but Typed Lua’s existing type system and Fabio’s goal for the class system distinguished this project from my previous work in some interesting ways:
Structural vs. Nominal Typing
Structural subtyping is sometimes called “duck typing” by programmers, a term inspired by the phrase “If it walks like a duck and quacks like a duck, it’s a duck”. In a nutshell, if a function expects an argument belonging to class A, but the programmer applies it to an object of class B, the application will be permitted so long as every public method and field of A is also a public method of field of class B.
Structural subtyping can be convenient, but also error prone, for if we had two classes Stack and Queue with Push and Pop methods, structural subtyping would allow us to use the two classes interchangeably. Unfortunately, this doesn’t account for the distinction between the two sets of equational laws that each class imposes on its instances: stacks are LIFO containers, whereas queues are FIFO containers.
Nominal subtyping is familiar to most programmers from languages such as Java: we are not allowed to use objects of class B where objects of class A are expected unless class B explicitly inherits from class A. With nominal typing the implementor of class B is responsible for ensuring that it does not violate A’s equational laws.
F-Bounded Polymorphism
Fabio initially wanted to use structural subtyping for the Typed Lua class system. However, we also wanted generics (i.e. type parameters) with comparable functionality to popular OOP langauges such as Java. Such class systems have an interesting feature known as F-Bounded polymorphism. F-Bounded polymorphism is an extension of bounded polymorphism. Bounded polymorphism allows us to place constraints on the types which may be used to instantiate a generic function:
interface Printable
method print () => ()
end
local function PrintAll< A <: Printable >(l : List<A>)
for v in elements(l) do
v:print()
end
end
In the above function PrintAll, the type parameter A can only be instantiated with classes that implement the Printable interface (Printable is called the bound). F-Bounded polymorphism allows the bound of the type parameter to refer to the parameter itself:
interface Ordered<T>
method lessThanEq : (T) => (boolean)
end
local function comparable< T <: Ordered<T> >(x : T, y : T) : boolean
return (x:lessThanEq(y) or y:lessThanEq(x))
end
State-of-the-art nominal type systems with F-Bounded polymorphism are more expressive than their structural counterparts, and for this reason we ultimately decided to use nominal class types.
Even with nominal subtyping, F-Bounded polymoprhism and its interaction with other features can be quite tricky to get correct. For example, Java’s implementation has fundamental flaws: Kennedy and Pierce reduced the problem of deciding Java’s subtyping relation to the Post Correspondence Problem, an famously undecidable problem from the theory of computation. We decided to use Greenman et al.’s approach, which requires the programmer to distinguish between interfaces that define materials (describing actual runtime objects) and interfaces which define shapes (interfaces used solely as type parameter bounds).
Game Kitchen: A Lua IDE and optional type system before optional type systems were cool
Back in 2010, I worked as a programmer at a video game company called Budcat Creations. I was tasked with creating an editor for the Lua scripting language. At one point, I was asked to add some primitive static type checking to the editor. I said that I had no idea how type checking worked, but they told me to do it regardless. To learn about type systems, I started reading the book Types and Programming Languages by Benjamin Pierce.
Soon after that, I quit Budcat to attend the University of Iowa as an undergrad. During my time as an undergrad, I kept reading Types and Programming Languages. To apply some of the ideas that I was reading about in a practical setting, I started programming a Lua IDE called Game Kitchen as a side project, targeting the game programming framework LOVE.
Game Kitchen has a built-in optional type checker for Lua, in which type annotations are provided through comment embedded type syntax. I thought that embedding type syntax in comments rather than replacing Lua’s existing syntax would make the type checker easier to adopt in an industrial setting. Adopting the type system could be considered a cautious, conservative choice: because type-annotated code is still compiled by the standard lua compiler, anyone unhappy with the type checker could simply stop using it.
A text-based alternative to the above video.
From developing Game Kitchen, I learned about some about important issues that arise in static typing. Here are a couple of examples:
Bidirectional type checking
Lua is often used as a data description language. With type annotations, we can provide schemas for data description.
Type definitions:
Theme = {
normal : Image,
active : Image,
activePressed : Image,
pressed : Image
}
GUIButton = {
theme : Theme,
-- the left x-coordinate of the button
x : number,
-- the top y-coordinate of the button
y : number,
-- the width of the button (using the images' width as default)
w : ?number,
-- the height of the button (using the images' width as default)
h : ?number
}
Data definition:
--@var(GUIButton)
local myButton = {
theme = {
normal = simpleButtonNormal,
active = simpleButtonActive,
activePressed = simpleButtonActivePressed,
pressed = "simpleButtonPressed"
}
...
}
In the above data definition, the pressed field has a type error: it is assigned to a string when it should be assigned to an Image according to the definition of the Theme type. A naive course of action would be to insert a red squiggly under the entire definition of myButton, since it does not conform to its ascribed type GUIButton. However, with bidirectional type checking we can do better: We can provide an explanation of why myButton does not conform to the GUIButton type, giving the red squiggly a more precise placement beneath the definition of the pressed field.
Bidirectional type checking has two modes: check and synthesize. Under check mode, type checking is performed with respect to an expected type. The type annotation GUIButton tells us that the definition of myButton should be checked with respect to the expected type GUIButton. To do this, we check that it has field theme, x, y, w, and h, which conform to types Theme, number, number, ?number, and ?number, respectively. We start by checking theme; the definition of myButton does have a field called theme, so we recurse into the definition of theme with the expected type set to Theme. Theme defines a field called pressed of type Image, and because theme defines an image field, we recurse into its definition, expecting find the type Image. However, we find the type “string” instead. Bidirectional type checking has allowed us to pinpoint the source of the type error rather than naively placing it at the location of the type ascription. How useful!
Equirecursive subtyping
If and are types, write for the product type formed from A and B. How can we decide if is a subtype of ? This holds whenever A1 is a subtype of A2 and B1 is a subtype of B2. Right? Well, yes. But that isn’t always easy to determine when recursive types are involved. Define and . Then, applying the aforementioned approach, is a subtype of whenever is a subtype of and… is a subtype of ? This is not a tenable subtyping algorithm because it reduces a subtyping query into a larger subtyping query containing the original.
Recursive subtyping queries are generally more tricky than the above example: we could define and . But devising an algorithm to determine this is non-trivial. In Game Kitchen, I adopted the approach described in chapter 21 of “Types and Programming Langauges”.
Raytracing in One Weekend
This is a fairly small project; I’m including it here simply to show that I have been brushing up on C++ and 3D math recently. This August, I worked through Peter Shirley’s tutorial “Ray Tracing in One Weekend”. All of the code is provided in the tutorial (though there are some minor mathematical errors that require spotting). For my own implementation, I translated Shirley’s code into C++17.

My implementation can be found on github.